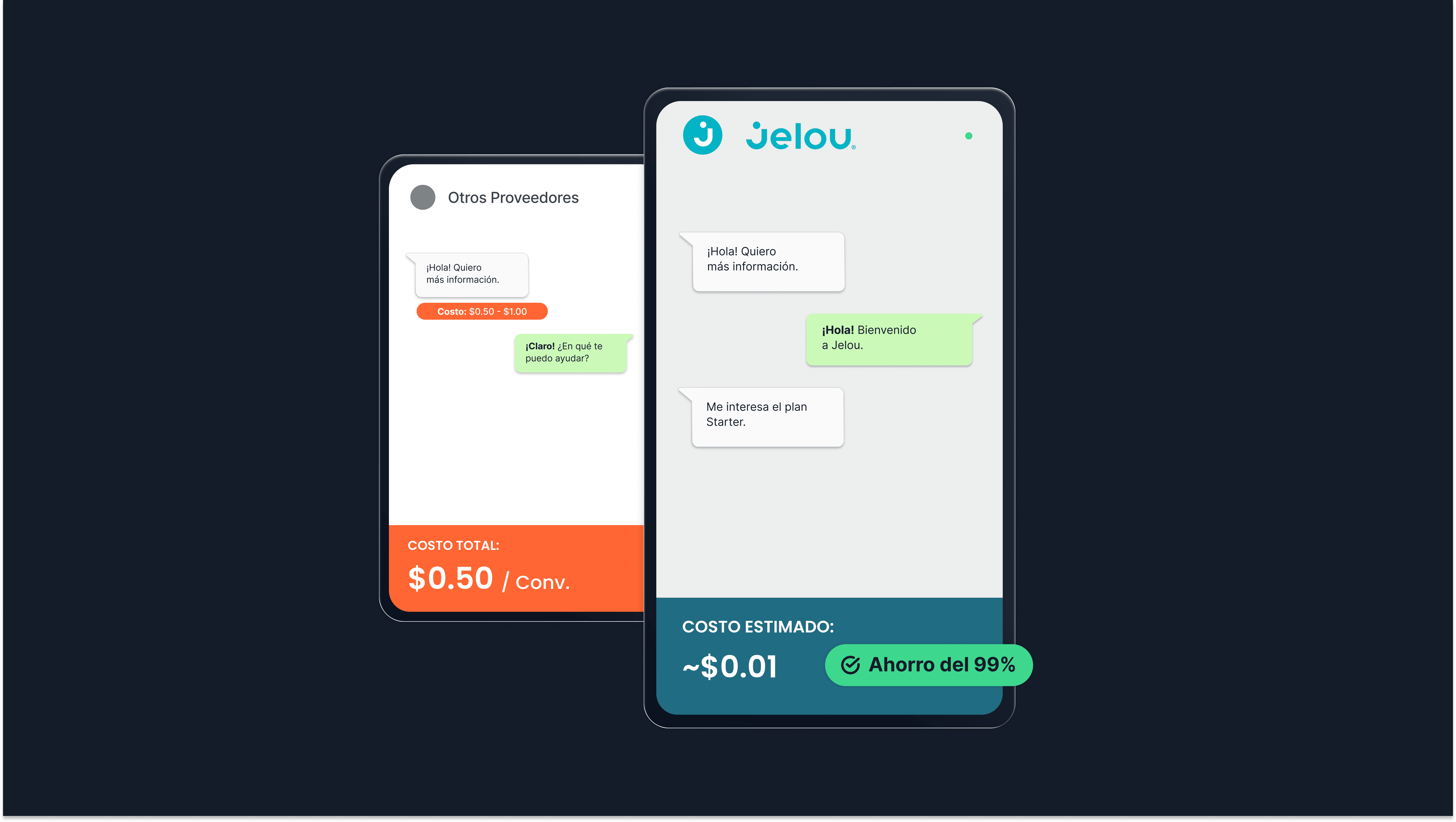
For a long time, the standard model for WhatsApp platforms was charging per conversation. At first glance, it makes sense: if there’s a conversation, you charge for it. Easy to explain. Seemingly simple to measure.
But when you look closer, that model has a structural issue. It directly affects how you design your product, and how your costs scale.
The Problem with Charging Per Conversation
Charging per conversation means a single message triggers the full cost. A simple “hi” instantly becomes a billable conversation, even if there’s no buying intent, no real system usage, and no value created for anyone.
Think about everything that falls under that same fixed cost: greetings, clarifications, short messages, internal testing, product iterations. A simple three-message flow costs the same as a forty-message flow with complex logic, tool calls, and AI processing.
That’s not a pricing model that encourages you to promote your product. If two thousand people message you just to say hello, you’ve already spent $1.000 (at $0,50 per conversation). No sale happened, but the cost is there.
For companies selling directly through WhatsApp or those with the budget to absorb it, this model can work. But for conversational products that don’t monetize every interaction, the cost becomes disconnected from the value created.
When Pricing Doesn’t Reflect Real Usage
When pricing doesn’t reflect what’s actually happening, product decisions start to shift. You focus on reducing conversations instead of improving the experience. You prioritize revenue-generating flows while neglecting support or service use cases. You avoid building more helpful experiences because every new interaction carries a fixed cost.
Pricing stops being a reflection of value and becomes a constraint on what you’re willing to build.
The Alternative: Charging for What the System Actually Does
A model based on executions and tokens flips that logic. Instead of charging because someone sent a message, you charge for what the system actually processed.
If your flow is simple and efficient, the cost stays low. If it’s more complex and uses more compute or integrations, the cost scales proportionally. No surprises. No hidden cross-subsidies.
| Per Conversation | Per Execution & Tokens | |
|---|---|---|
| A “hi” with no meaningful outcome | Full conversation cost | Minimal cost (few tokens) |
| Internal test message | Full conversation cost | Minimal cost |
| Simple 3-message flow | Full conversation cost | Low, usage-based cost |
| Complex flow with AI, APIs, logic | Full conversation cost | Higher, processing-based cost |
| 40-message flow with tools and logic | Full conversation cost | Cost reflects actual work done |
The difference is simple: in a per-conversation model, everything costs the same regardless of value. In an execution-based model, you pay for what you use.
Why This Matters for Your Product
When pricing aligns with real usage, you can make product decisions without fear. You can iterate faster, test new flows, and improve user experience without every experiment feeling like a financial risk.
An execution-based model is more transparent, more predictable, and more aligned with how conversational products actually operate. It doesn’t penalize user activity. It charges for the real work your system performs.
And that fundamentally changes how you build.