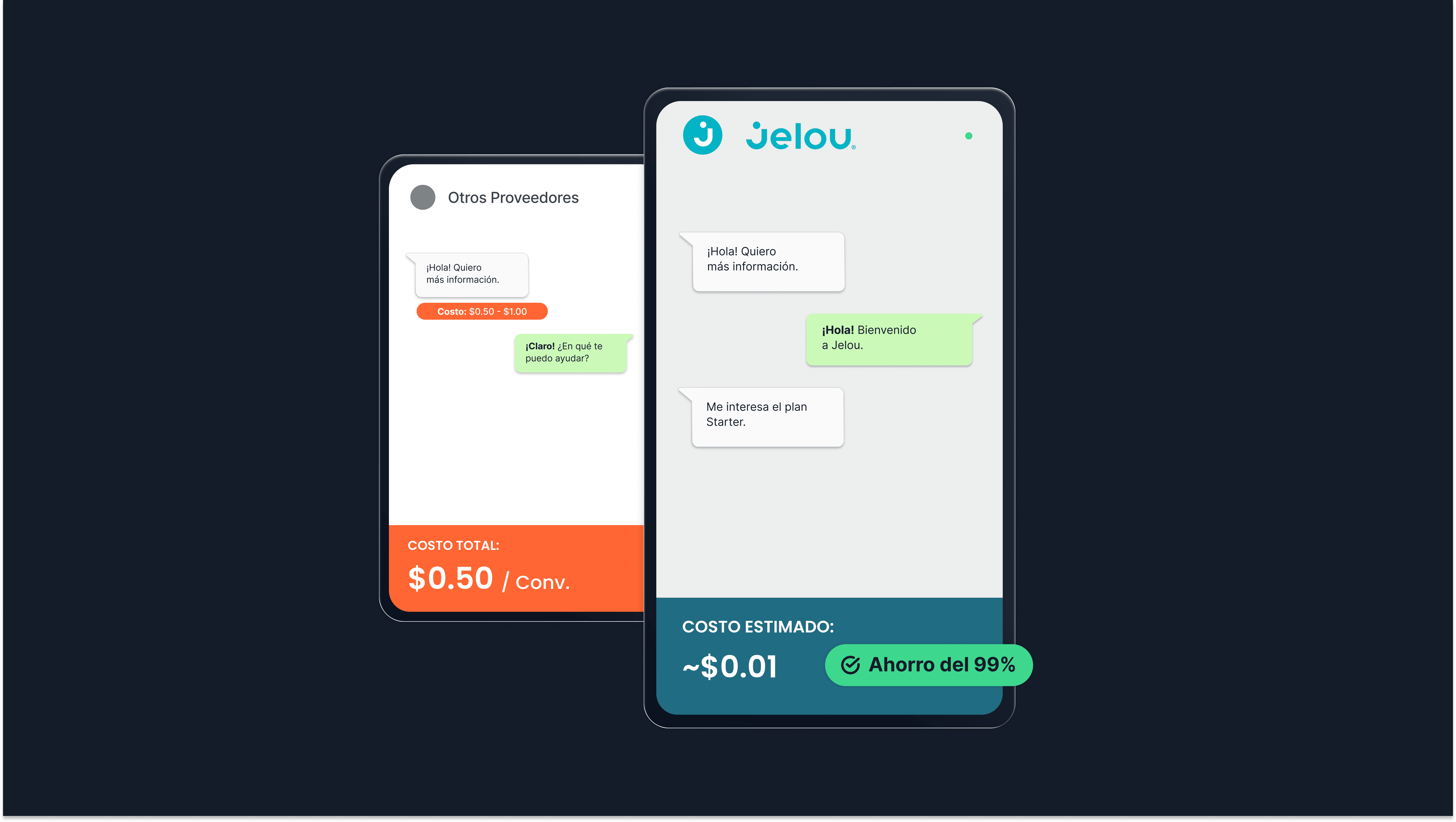
Durante muito tempo, o modelo padrão para plataformas de WhatsApp foi cobrar por conversa. À primeira vista, faz sentido: se houve uma conversa, cobra-se por ela. Fácil de explicar. Aparentemente simples de medir.
Mas, olhando mais de perto, esse modelo tem um problema estrutural. Ele afeta diretamente como você desenha seu produto, e como seus custos escalam.
O problema de cobrar por conversa
Cobrar por conversa significa que uma única mensagem já ativa o custo completo. Um simples “oi” se transforma automaticamente em uma conversa faturável, mesmo que não haja intenção de compra, uso real do sistema ou valor gerado.
Pense em tudo que entra nesse mesmo custo fixo: saudações, esclarecimentos, mensagens curtas, testes internos, iterações de produto. Um fluxo simples de três mensagens custa o mesmo que um fluxo de quarenta mensagens com lógica complexa, chamadas a ferramentas e processamento de IA.
Esse não é um modelo de precificação que incentiva você a promover seu produto. Se duas mil pessoas enviarem apenas um “oi”, você já gastou US$ 1.000 (a US$ 0,50 por conversa). Nenhuma venda aconteceu, mas o custo já foi gerado.
Para empresas que vendem diretamente pelo WhatsApp ou que têm orçamento para absorver esse custo, o modelo pode funcionar. Mas, para produtos conversacionais que não monetizam cada interação, o custo deixa de estar alinhado com o valor criado.
Quando o preço não reflete o uso real
Quando o preço não reflete o que realmente está acontecendo, as decisões de produto começam a mudar. Você passa a tentar reduzir conversas em vez de melhorar a experiência. Prioriza apenas fluxos que geram receita e deixa de lado atendimento ou suporte. Evita criar experiências mais úteis porque cada nova interação representa um custo fixo adicional.
O preço deixa de ser consequência do valor gerado e passa a ser uma limitação do que você está disposto a construir.
A alternativa: cobrar pelo que o sistema realmente faz
Um modelo baseado em execuções e tokens inverte essa lógica. Em vez de cobrar porque alguém enviou uma mensagem, você cobra pelo que o sistema realmente processou.
Se o fluxo for simples e eficiente, o custo é baixo. Se for mais complexo e exigir mais processamento ou integrações, o custo escala de forma proporcional. Sem surpresas. Sem subsídios cruzados ocultos.
| Por conversa | Por execução e tokens | |
|---|---|---|
| Um “oi” sem resultado relevante | Custo completo da conversa | Custo mínimo (poucos tokens) |
| Mensagem de teste interna | Custo completo da conversa | Custo mínimo |
| Fluxo simples de 3 mensagens | Custo completo da conversa | Custo baixo, proporcional ao uso |
| Fluxo complexo com IA, APIs e lógica | Custo completo da conversa | Custo maior, proporcional ao processamento |
| Fluxo de 40 mensagens com ferramentas e lógica | Custo completo da conversa | Custo reflete o trabalho real executado |
A diferença é clara: no modelo por conversa, tudo custa o mesmo, independentemente do valor gerado. No modelo por execução, você paga pelo que realmente utiliza.
Por que isso importa para o seu produto
Quando a precificação está alinhada com o uso real, você pode tomar decisões de produto sem medo. Pode iterar mais rápido, testar novos fluxos e melhorar a experiência do usuário sem que cada experimento pareça um risco financeiro.
Um modelo baseado em execuções é mais transparente, mais previsível e mais alinhado com a forma como produtos conversacionais realmente funcionam. Ele não penaliza a atividade dos usuários. Ele cobra pelo trabalho real que o sistema executa.
E isso muda completamente a maneira como você constrói.
